RAG vs Fine-Tuning: A Comprehensive Evaluation
The RAG vs Fine-Tuning debate is always interesting, so when this comprehensive evaluation study was released, I had to read it.
What They Covered
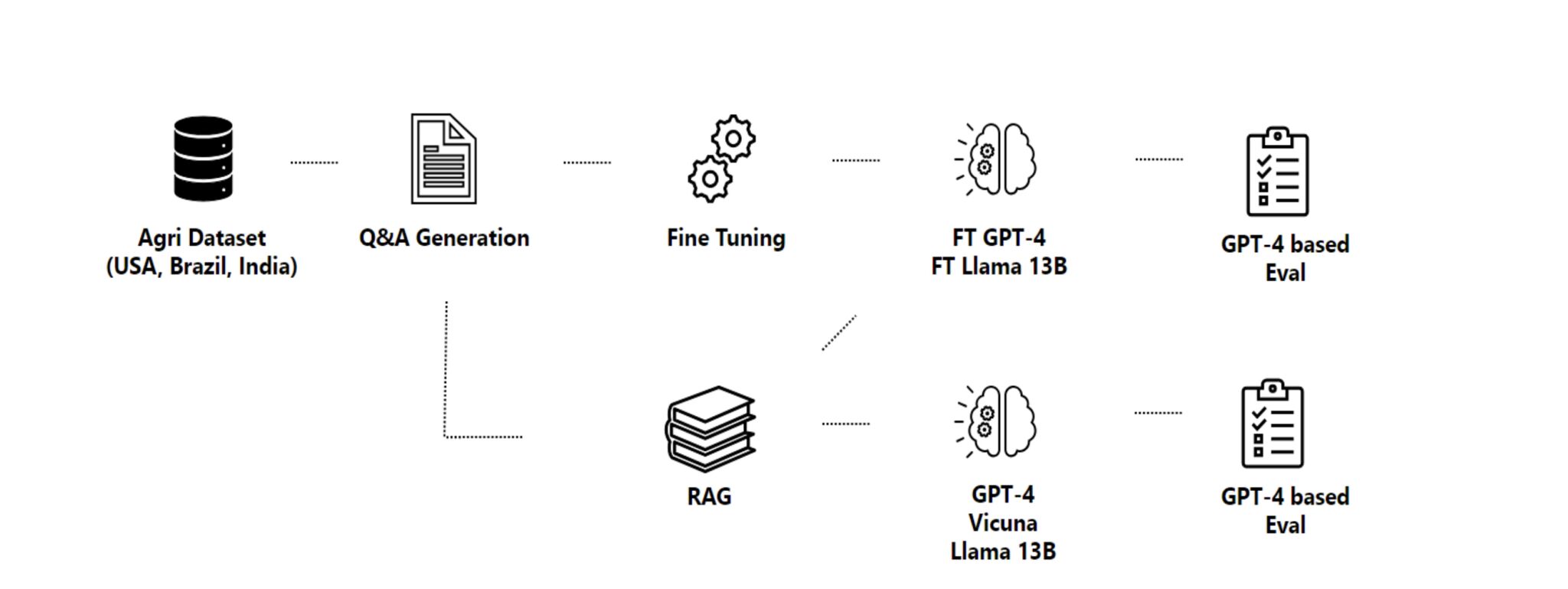
A comprehensive evaluation of LLMs including base models, with RAG, and with fine-tuning. It involved data collection, extraction, assessing data and model quality, and a series of experiments.
How They Went About It
They start by gathering domain-specific data (agriculture), extracting information, and creating Question and Answer (Q&A) pairs, then fine-tuning the models with these pairs.
Models Used
GPT-4, GPT-3.5, Llama2-13B, Llama-2-chat-13B, and Vicuna. They also use Facebook AI Similarity Search (FAISS) to create a database of the embeddings.
Results
- Data Extraction: JSON proved most effective for extracting data from complex hierarchical documents
- Q&A Generation: GPT-4 excelled in all metrics but tended to produce verbose outputs
- Retrieval: Increasing ‘k’ in Top-k improved recall but decreased with larger indexes due to collisions
- Fine-Tuning vs. RAG: GPT-4 consistently outperformed others. Models show a cumulative increase in performance when both fine-tuning and RAG are used together
The Tradeoff
The low initial cost of RAG can make it an attractive option, however it is important to consider the input token cost of the prompt. Fine-tuning on the other hand produces precise and succinct outputs with a high initial cost and extensive work involved in the fine-tuning process.